
How Embeddings and Vector Stores Work, and Why LangChain Makes It Easy
A plain-English guide to the technology that lets AI find meaning, not just keywords.

If you’ve ever wondered how a chatbot can answer a question even when you word it differently every time, or how a search engine surfaces results that feel right even without exact matches, the answer lies in two powerful ideas: embeddings and vector stores.
Let’s break both down from scratch.
What is an embedding?
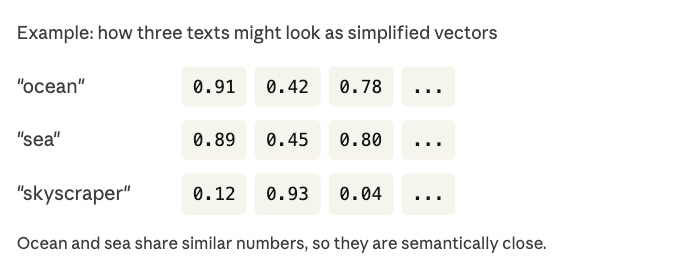
An embedding is simply a way of turning text into numbers, specifically a list of numbers called a vector.
Think of it like a map. Just as you can describe any location with two numbers (latitude and longitude), you can describe the “meaning” of any piece of text using hundreds of numbers. Similar meanings end up near each other on that map.
That’s the magic. The words “ocean” and “sea” don’t mean exactly the same thing, but their vectors end up very close together in this numerical space. “Ocean” and “skyscraper”? Miles apart.
What is a vector store?
Once you’ve turned all your documents into vectors, you need somewhere to keep them and a way to search them fast. That’s what a vector store is.
A normal database looks for exact matches:
sql
SELECT * FROM table WHERE name = 'John'
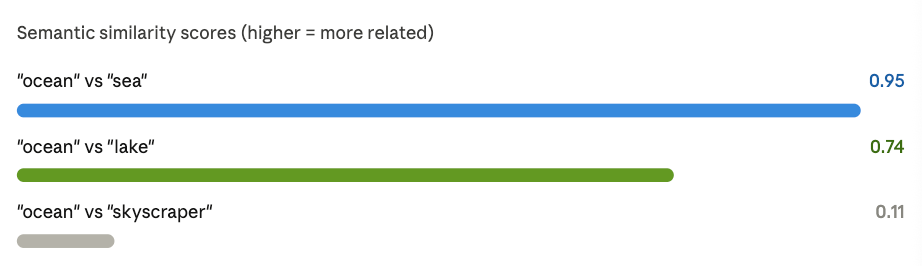
A vector store works differently. It finds the vectors that are closest in meaning to your query. This is called a similarity search or nearest-neighbor search.
Instead of asking “does this document contain this exact word?” a vector store asks “which documents are most similar in meaning to this query?
How does it measure similarity?
Two popular methods are used under the hood to measure similarities between embeddings (aka vectors) :
Cosine similarity
Imagine two arrows pointing in different directions. Cosine similarity measures the angle between them. A small angle (arrows nearly parallel) means very similar meaning. A large angle means very different. It doesn’t care about the length of the arrows, just the direction.
Dot product
The dot product multiplies matching numbers from two vectors and adds them all up. A high result means the vectors align well, both in direction and magnitude. It’s faster to compute, which makes it popular in large-scale systems.
Where LangChain comes in
All of this, embedding text, storing vectors, running similarity searches, involves a lot of moving parts. LangChain wraps it all into a clean, consistent interface so you don’t have to reinvent the wheel.
Here’s what happens under the hood when you add documents in LangChain:
LangChain calls your chosen embeddings model to convert each document into a vector.
It pairs each vector with the original text and any metadata you want to keep (like a title or source URL).
Everything gets inserted into the vector store, ready to be searched.
When you run a query, LangChain embeds your question the same way, then uses cosine similarity or dot product to find the most relevant stored documents and hands them back to you in seconds.
Which vector store should you use?
LangChain supports everything from a lightweight in-memory store for quick testing all the way to production-grade databases for real applications.
The beauty of LangChain is that your application code barely changes when you switch between them. Just swap the store and keep everything else the same.
What can you build with this?
Once you have embeddings and a vector store in place, the door opens to a wide range of AI-powered applications:
🔍 Semantic search - find documents by meaning, not keywords
💬 Q&A bots - answer questions directly from your own documents
📚 RAG systems - ground AI responses in your own data
🎯 Recommendation engines - surface similar content based on what a user is reading
Wrapping up
Vector stores are a foundational piece of modern AI apps. By converting raw text into meaningful embeddings and indexing them in a specialized database, you can build tools that understand what people mean, not just what they literally type.
And with LangChain handling the plumbing, you can go from idea to working prototype in just a few lines of code, whether you’re experimenting locally or shipping to production.